数据的产生及信息爆炸带来的挑战
为了更清晰的认识我们所生存的环境,提高人际沟通效率,人们收集和创造了大量的数据,有些是对物理世界的客观描述,如原子和分子的组成,或是DNA螺旋结构;也包括烟波浩渺的宇宙中的星系和星云;亦或是人类对自身历史的记录;还有一些数据被用于人们相互沟通,如Facebook上每天新增数十亿条内容,或每天被发送的数千亿封邮件。
随着人们对客观世界的逐步认知,人际沟通的效率越来越高,人们的沟通与生活也越来越丰富,人类收集和创造的数据也越来越多,这些数据饱含信息与知识,是人类智慧与勤劳的结晶,是人类宝贵的信息资产。一部《史记》,共52万6千500字,约1MB数据;一组用于基因研究的染色体照片数据量超过2TB;欧洲核子研究中心(CERN)每年有超过20PB数据通过全球***的大型强子对撞机(LHC)被收集起来用于微观粒子研究。根据IDC的分析,2011年全球数据产生量达到1.8ZB,到2020年这个数字将增长50倍(1ZB=1,000EB=1,000,000PB),如此大规模的数据给存储系统带来了巨大的挑战,人类将如何应对咆哮而来的数据洪流?
存储方案的演进
在人类发明和使用电子计算机以前,数据处理由人类大脑完成,大脑中还同时存储了大量信息用于支撑数据处理,人类大脑存储的信息依然相对有限,仍有大量数据被存储在图书馆。当有需要的时候,人们便会到图书馆获取更多的数据。以此我们可以总结出如下的一种数据存储与数据处理模型:

该模型包括三个部分,计算单元、内部存储单元(低延迟,容量偏小)、外部存储单元(延迟增加,容量超大)。如果按照对图书的存储(记忆)能力来估算,通常一个人大脑中能记忆的内容不超过1000本书,图书馆中收藏的书籍大约是百万本为单位。两种存储的存储容量差距大概是1000倍,而且图书馆中的数据可以被很多人共享。
20世纪电子与信息技术迅速发展,机器计算迅速普及,冯·诺依曼在1945年6月30日,提出了存储程序逻辑架构,即现有的计算机都遵循的"冯·诺依曼体系架构",具体如下图:

我们可以看出,冯诺依曼体系结构与人脑(生物)计算模型匹配度相当准确。我们通常把运算器和控制器合并成中央处理器(CPU),内部小容量的存储提供快速的访问,外部存储器提供大容量的存储空间。在不同的计算机时代,我们可以按照不同的角度来理解冯诺依曼体系结构。在单机计算时代(包括大型机、小型机、微机)内部存储器可理解为内存(即Memory),外部存储器可理解为物理硬盘(包括本地硬盘和通过网络映射的逻辑卷)。在本地硬盘空间不足,可靠性无法满足业务需求的情况下,SAN存储出现了,通过网络映射的逻辑卷(即SAN存储提供的LUN)成为增强版的硬盘。为了解决数据共享的问题,NAS存储随之诞生。
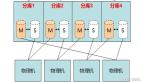
但冯诺依曼体系架构没有考虑并行计算和数据共享情形,在如今的网络时代,大量计算设备通过网络形成一个庞大、相互独立但又逻辑统一的计算系统,因此我们可以总结出一个数据存储的通用模型,这个模型包括两级存储,其存储容量差距约1000倍:

如果将上图中每一个计算模块理解为一个计算内核,那么高速存储单元则是CPU内的缓存(单位为KB~MB),海量存储单元则是内存(单位为GB);如果把每一个计算模块理解为一个CPU,那么高速存储单元则是内存(单位为GB~TB),海量存储是物理硬盘或通过网络映射给服务器的逻辑卷(或网络文件系统,单位为TB~PB);如果把计算模块理解为针对某一项任务或某一组任务提供计算能力的服务器集群,把SAN或NAS等拥有TB~PB级存储规模的网络存储设备理解为高速存储单元,那么具备PB~EB级存储容量的海量存储单元将基于什么技术和产品构建呢?

SAN和NAS技术已经出现了数十年,目前单台SAN或NAS设备***容量已经达到PB级别,但在应对EB级数据挑战时,还是显得有些力不从心。这主要由于其架构和服务接口决定的。
SAN使用SCSI协议作为底层协议,SCSI协议管理的粒度非常小,通常以字节(byte)或千字节(KB)为单位;同时SCSI协议没有提供读写锁机制以确保不同应用并发读写时的数据一致性,因此难以实现EB级存储资源管理和多个服务器/服务器集群之间数据共享。
NAS使用文件协议访问数据,通过文件协议存储设备能够准确识别数据内容,并提供了非常丰富的文件访问接口,包括复杂的目录/文件的读写锁。文件和目录采用树形结构管理,每个节点使用一种叫做inode的结构进行管理,每一个目录和文件都对应一个iNode。目录深度或同一目录下的子节点数随着整体文件数量的增加而快速增加,通常文件数量超过亿级时,文件系统复杂的锁机制及频繁的元数据访问将极大降低系统的整体性能。
传统的RAID技术和Scale-up架构也阻止了传统的SAN和NAS成为EB级高可用,高性能的海量存储单元。传统的RAID基于硬盘,通常一个RAID组最多包含20+块硬盘,即使PB级规模的SAN或NAS也将被分割成多个存储孤岛,增加了EB级规模应用场景下的管理复杂度;同时Scale-up架构决定了即使SAN和NAS存储容量达到EB级,性能也将成为木桶的短板。
那么如何才能应对信息爆炸时代的数据洪流呢?我们设想能否有一种"超级数据图书馆",它提供海量的、可共享的存储空间给很多用户(服务器/服务器集群)使用,提供超大的存储容量,其存储容量规模千倍于当前的高速存储单元(SAN和NAS),用户或应用访问数据时无需知道图书馆对这些书如何摆放和管理(布局管理),只需要提供唯一编号(ID)就可以获取到这本书的内容(数据)。如果某一本书变得老旧残破,系统自动地将即将失效或已经失效的书页(存储介质)上的数据抄写(恢复/重构)到新的纸张(存储介质)上,并重新装订这本书,数据使用者无需关注这一过程,只是根据需要去获取数据资源。这种"超级数据图书馆"是否真的存在呢?
分布式对象存储的诞生
对象存储技术的出现和大量自动化管理技术的产生,使得"超级数据图书馆"不再是人类遥不可及的梦想。对象存储系统(Object-Based Storage System)改进了SAN和NAS存储的劣势,保留了NAS的数据共享等优势,通过高级的抽象接口替代了SCSI存储块和文件访问接口,屏蔽了存储底层的实现细节,将NAS垂直的树形结构改变成平等的扁平结构,从而提高了扩展性、增强了可靠性、具备了平台无关性等重要存储特性。
SNIA(网络存储工业协会)定义的对象存储设备是这样的:
◆对象是自完备的,包含元数据、数据和属性
存储设备可以自行决定对象的具体存储位置和数据的分布
存储设备可以对不同的对象提供不同的QoS
◆对象存储设备相对于块设备有更高的"智能",上层通过对象ID来访问对象,而无需了解对象的具体空间分布情况
换句话说对象存储是智能化、封装得更好的块,是"文件"或其他应用级逻辑结构的组成部分,文件与对象的对应关系由上层直接控制,对象存储设备本身也可能是个分布式的系统--这就是分布式对象存储系统了。
用对象替代传统的块的好处在于对象的内容本身来自应用,其具有内在的联系,具有"原子性",因此可以做到:
◆在存储层进行更智能的空间管理
◆内容相关的数据预取和缓存
◆可靠的多用户共享访问
◆对象级别的安全性
同时,对象存储架构还具有更好的可伸缩性。一个对象除了ID和用户数据外,还包含了属主、时间、大小、位置等源数据信息,权限等预定义属性,乃至很多自定义属性。
具备EB级规模扩展性的分布式对象存储,通过对应用提供统一的命名空间,构建EB级统一、可共享数据的存储资源池,有效地填补上述通用计算模型中"网络计算"场景海量存储单元空白,通过高层次的数据模型抽象,可以简化应用对数据访问,同时使得海量存储更加智能。
华为公司基于对电信运营商、大型企业、互联网、科学研究等领域的深刻理解,凭借深厚的ICT技术积累,秉承存无止境,安全可信理念,通过不断技术创新,推出新一代UDS海量存储系统。
对象是数据和自描述信息的集合,是在磁盘上存储的基本单元。对象存储通过简化数据的组织形式(如将树形的"目录"和"文件"替换为扁平化的"ID"与"对象")、降低协议与接口的复杂度(如简化复杂的锁机制,确保最终一致性),从而提高系统的扩展性以应对信息爆炸时代海量数据的挑战。同时对象的智能自管理功能也能有效降低系统维护复杂度,帮助用户降低整体拥有成本(TCO)。
华为UDS开创性地采用基于ARM芯片的高密度硬件架构,降低单位容量功耗、提高单位体积存储容量,有效降低能源消耗;通过对象、P2P分布式存储引擎、集群应用等技术构建海量对象存储基础架构平台;对外提供多种访问接口,以满足不同业务的适配需求。以UDS为基础可构建多种解决方案,如海量资源池,网盘,云备份,集中备份等方案将帮助用户构建强扩展,易管理,高可靠的"超级数据图书馆",使得人类可以轻松应对海量存储环境下的各种挑战。
华为UDS(Universal Distributed Storage)海量存储系统以对象作为基本存储形式,通过分布式技术将本地或异地海量存储节点的存储资源进行有机的整合,形成一个跨地域、跨设备、可横向扩展的EB级容量的大型分布式对象存储系统;该系统通过多种安全、可靠的存储技术确保数据私密性及数据高可用;通过自动化部署、自动负载均衡、自动数据迁移、故障自愈等技术丰富自动化管理特性,同时结合丰富的生命周期管理策略及高效节能技术,提高运维效率。华为UDS海量存储系统为客户构建数字洪流时代的"超级数据图书馆",帮助客户化挑战为机遇,并在信息化社会发展中持续受益。